
Zuverlässigkeit in Fintech-Services meistern
Von Versprechen zu Nachweisen: SLA, SLO und echte Verfügbarkeit


Fehlerbudgets als Hebel für Produkttempo

Prüfpfade und Nachvollziehbarkeit stärken
Meldepflichten und Kommunikationspläne
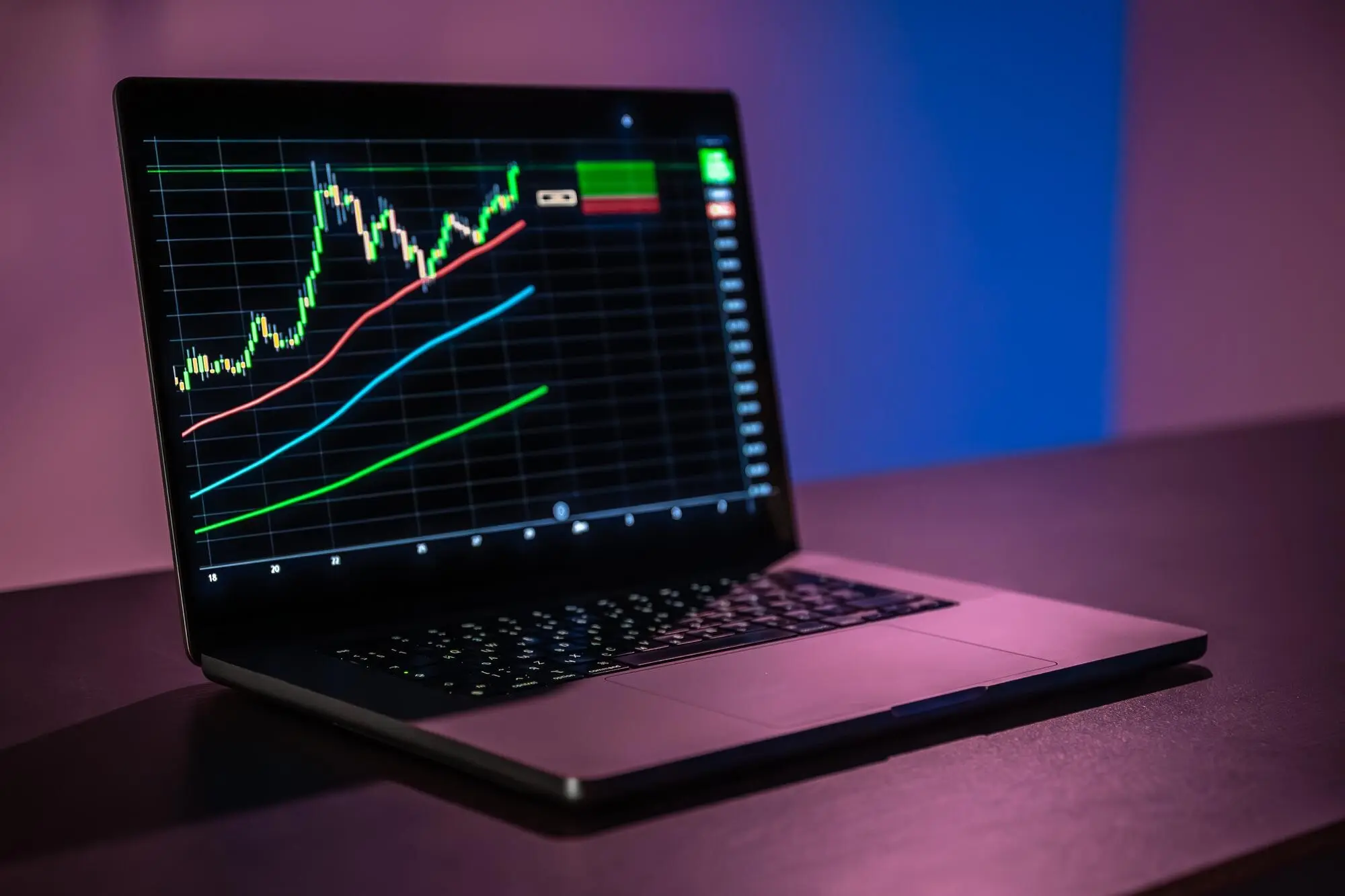
Observability und finanzspezifische Metriken, die zählen

Incident‑Response, Lernkultur und nachhaltige Stabilität
Runbooks, die Entscheidungen erleichtern
Gute Runbooks listen nicht nur Schritte, sie bieten Wahlbäume, Eskalationshinweise und Erfolgskriterien. Wir formulieren minimalistische, testbare Anweisungen mit klaren Rollenzuordnungen, Links zu Dashboards und Kommunikationsvorlagen. Regelmäßige Game‑Days halten sie frisch. So sinkt kognitive Last, und First‑Fix‑Time verbessert sich deutlich. Teile ein Beispiel, und wir helfen, es in eine praxistaugliche Entscheidungsunterstützung zu verwandeln.
Stakeholder‑Kommunikation mit ruhiger Hand
Während Vorfällen brauchen Kunden, Management und gegebenenfalls Aufsicht verlässliche, konsistente Informationen. Wir strukturieren Updates nach Wirkung, Ursache, Gegenmaßnahmen und nächstem Meilenstein. Klare Timestamps, abgestimmte Kanäle und eine Evidenzliste vermeiden Widersprüche. Templates beschleunigen Freigaben, ohne Präzision zu opfern. So bleibt Vertrauen erhalten, selbst wenn die Lage komplex ist. Teile eure Kommunikationswege, und wir verbessern Taktung sowie Tonalität.
Aus Incident‑Daten Roadmaps bauen
Postmortems sind erst der Anfang. Wir verknüpfen wiederkehrende Ursachen mit SLO‑Gaps, schätzen Budgetwirkung, und priorisieren strukturiert. Transparente Backlogs verhindern Déjà‑vu‑Fehler und stärken Incentives für Qualitätsarbeit. Management erkennt den Nutzen technischer Schuldenabbau‑Stories. Abonniere unsere Leitfäden, und erhalte Vorlagen für Metrik‑gestützte Priorisierung, die Revisionssicherheit, Produktfokus und Teamgesundheit gleichermaßen beachten.
Architekturentscheidungen für resiliente Finanzplattformen

Mehrregionale Zahlungen ohne Doppelbuchungen
Abhängigkeiten von Drittanbietern steuern
Testen unter Aufsicht: Chaos, Abschaltungen, Rehearsals
All Rights Reserved.